
The best AIOps tools in 2026 help organizations automate IT operations, reduce alert fatigue, improve root cause analysis, and accelerate incident response across hybrid and cloud-native environments.
Leading AIOps platforms such as Dynatrace, Datadog, Splunk ITSI, New Relic, and LogicMonitor combine machine learning, observability, and automation to improve operational efficiency and service reliability.
Introduction
Modern IT environments are becoming more complex every year. Organizations now manage applications, servers, cloud services, containers, networks, and endpoints across multiple platforms.
Most businesses no longer operate from a single data center. Instead, they use a hybrid infrastructure that combines on-premises systems with public and private cloud services.
At the same time, cloud-native environments continue expanding. Technologies such as Kubernetes, microservices, and distributed applications generate massive amounts of operational data every minute.
This growth creates a new challenge for IT teams.
Traditional monitoring tools collect huge volumes of logs, metrics, events, and alerts. As infrastructure grows, the number of notifications increases rapidly. Many IT teams struggle to identify which alerts require immediate attention.
This problem is commonly known as alert fatigue.
When administrators receive thousands of alerts daily, important incidents can become difficult to detect. Troubleshooting also becomes slower because teams must analyze data from multiple monitoring systems.
AIOps addresses these challenges through artificial intelligence and machine learning.
AIOps tools analyze large volumes of operational data in real time. They identify abnormal behavior, correlate related events, and help teams find root causes faster. Many platforms can also automate routine operational tasks and incident response workflows.
AIOps tools use artificial intelligence and machine learning to automate IT operations, reduce alert fatigue, detect anomalies, and improve incident response across cloud and hybrid environments.
As organizations continue adopting cloud-native technologies, manual monitoring becomes harder to scale. Businesses increasingly need intelligent platforms that can process operational data faster than human teams alone.
This is why AIOps adoption continues to grow across enterprises, managed service providers, and cloud-first organizations.
In this guide, we compare the best AIOps tools in 2026, explain how AIOps works, explore key features, and help you choose the right platform for your IT operations strategy.
What Is AIOps?
AIOps stands for Artificial Intelligence for IT Operations. It combines machine learning, big data analytics, and automation to improve how IT teams monitor, manage, and optimize modern technology environments.
Traditional monitoring tools generate large volumes of alerts, logs, and performance data. As infrastructure grows, analyzing this information manually becomes increasingly difficult.
AIOps platforms solve this problem by automatically processing operational data. They identify patterns, detect anomalies, correlate related events, and help teams respond to incidents faster.
In simple terms, AIOps uses artificial intelligence to transform raw IT data into actionable insights and automated operational decisions.
How AIOps Works
AIOps platforms continuously collect data from multiple sources across the IT environment.
These sources may include:
- logs,
- metrics,
- events
The platform analyzes this information using machine learning models and advanced analytics engines.
Instead of treating every alert separately, AIOps correlates related events into a single incident. This reduces alert noise and helps IT teams focus on the actual problem.
Many platforms also use predictive analytics to identify potential issues before they affect users. Some solutions can automatically trigger remediation workflows when predefined conditions occur.
As a result, IT teams spend less time investigating alerts and more time improving service reliability.
Core Components of an AIOps Platform
Most AIOps platforms include several core technologies that work together.
Data Collection
The platform gathers telemetry from applications, infrastructure, cloud services, networks, and monitoring tools.
Big Data Analytics
Analytics engines process large volumes of operational data in real time. This allows the platform to identify trends and unusual behavior quickly.
Machine Learning
Machine learning models learn normal system behavior over time. They detect anomalies that may indicate performance degradation, outages, or security issues.
Event Correlation
The platform groups related alerts into meaningful incidents. This reduces duplicate notifications and speeds up troubleshooting.
Automation
Automation workflows execute predefined actions without manual intervention. These actions may include restarting services, creating tickets, or triggering incident response procedures.
Together, these components create a smarter and more proactive approach to IT operations management.
AIOps vs Traditional IT Operations
Traditional IT operations rely heavily on manual monitoring and reactive troubleshooting.
Administrators often review alerts individually, investigate incidents manually, and perform repetitive operational tasks themselves.
This approach becomes difficult as infrastructure expands across cloud, hybrid, and distributed environments.
AIOps introduces intelligence and automation into the process.
Instead of simply displaying alerts, AIOps platforms analyze operational data, identify root causes, and recommend or execute corrective actions automatically.
The difference becomes even more important in cloud-native environments where thousands of events may occur every minute.
| Feature | Traditional IT Operations | AIOps |
| Monitoring | Manual and rule-based | AI-driven and adaptive |
| Alert Management | High alert volume | Alert correlation and noise reduction |
| Root Cause Analysis | Manual investigation | Automated analysis |
| Incident Response | Reactive | Proactive and predictive |
| Automation | Limited | Extensive workflow automation |
| Scalability | Difficult at a large scale | Designed for modern environments |
As IT environments continue growing in complexity, many organizations are adopting AIOps to improve operational efficiency, reduce downtime, and accelerate incident resolution.
Why Businesses Are Adopting AIOps Tools
Modern IT environments generate more operational data than ever before. Cloud applications, microservices, containers, and distributed infrastructure continuously produce logs, metrics, events, and alerts.
As environments become larger and more complex, traditional monitoring approaches struggle to keep pace.
Many IT teams face growing challenges such as alert fatigue, rising incident volumes, cloud complexity, and skilled staffing shortages. These pressures are driving organizations to adopt AIOps tools that can automate analysis, reduce manual effort, and improve operational efficiency.
AIOps platforms help businesses process massive amounts of operational data, identify critical issues faster, and respond to incidents with greater accuracy.
Reducing Alert Noise
One of the biggest operational challenges facing IT teams is alert overload.
Modern monitoring systems often generate thousands of alerts every day. Many of these alerts are duplicates, secondary symptoms, or low-priority notifications.
When administrators receive too many alerts, important incidents can become difficult to identify.
This creates alert fatigue.
AIOps platforms reduce alert noise through intelligent event correlation. Instead of displaying every alert individually, the platform groups related alerts into a single incident.
This approach helps teams focus on the root problem rather than investigating hundreds of disconnected notifications.
Fewer alerts mean faster decision-making and more effective incident response.
Accelerating Root Cause Analysis
Finding the source of an outage can be time-consuming.
Traditional troubleshooting often requires administrators to examine logs, metrics, dashboards, and infrastructure components separately. This process may take hours during complex incidents.
AIOps platforms speed up root cause analysis by automatically correlating operational data from multiple sources.
Machine learning models identify relationships between events and highlight the systems most likely causing the issue.
This reduces investigation time and allows teams to resolve incidents more quickly.
Faster diagnosis often leads to lower downtime and improved service availability.
Improving IT Team Productivity
Many organizations struggle to hire and retain experienced IT operations professionals.
At the same time, infrastructure complexity continues to increase.
This creates a gap between operational demands and available resources.
AIOps helps bridge this gap through automation.
Many platforms automatically perform tasks such as:
- incident classification,
- ticket creation,
- workflow execution.
This reduces repetitive manual work and allows IT teams to focus on strategic projects.
Instead of spending hours reviewing alerts, teams can concentrate on improving system reliability and performance.
Supporting Hybrid and Multi-Cloud Environments
Most modern businesses operate across multiple technology platforms.
A typical environment may include:
- on-premises infrastructure,
- public cloud services,
- SaaS applications.
Managing these environments with separate monitoring tools often creates visibility gaps.
AIOps platforms provide centralized operational intelligence across diverse environments.
They collect and analyze data from multiple infrastructure layers, cloud providers, and applications through a unified platform.
This broader visibility helps organizations identify issues that span multiple systems.
It also improves operational consistency across hybrid and multi-cloud deployments.
As businesses continue expanding their cloud footprint, centralized visibility and intelligent automation become increasingly important for maintaining reliable IT operations.
How AIOps Platforms Work
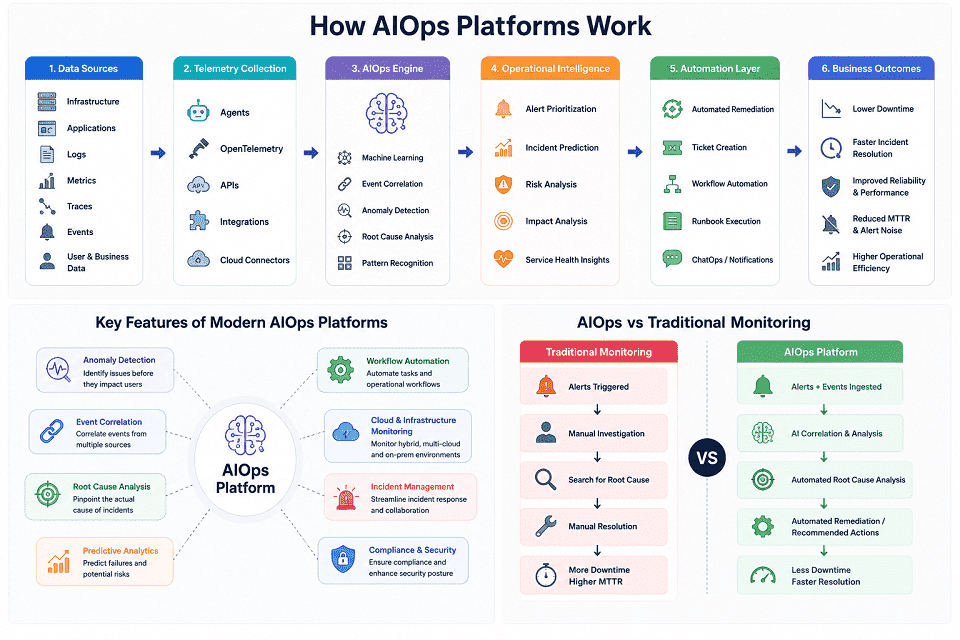 AIOps platforms transform operational data into actionable insights and automated responses. They continuously collect information from across the IT environment, analyze patterns using AI models, and help teams identify and resolve issues faster.
AIOps platforms transform operational data into actionable insights and automated responses. They continuously collect information from across the IT environment, analyze patterns using AI models, and help teams identify and resolve issues faster.
Modern IT infrastructures generate huge amounts of telemetry every second. This includes logs, metrics, traces, and operational events. Processing this information manually becomes increasingly difficult as environments grow.
AIOps platforms address this challenge by combining observability, machine learning, event correlation, and automation into a unified operational workflow.
Data Collection and Observability
Every AIOps platform begins with data collection.
The platform gathers telemetry from applications, servers, networks, cloud services, databases, and containers. Telemetry provides visibility into how systems perform and interact across the environment.
Logs record system activities and application events. Metrics measure performance indicators such as CPU usage, memory consumption, response times, and network throughput. Traces follow requests as they move through distributed applications and services.
Together, these data sources create the observability foundation that AIOps platforms use to understand system behavior.
Event Correlation
Large IT environments can generate thousands of alerts during a single incident.
Many alerts describe symptoms rather than the underlying problem. Investigating each alert individually wastes valuable time and resources.
AIOps platforms use event correlation to identify relationships between alerts. The platform groups connected events into a single incident and highlighted the most likely source of the problem.
This process reduces alert noise and gives operations teams a clearer view of what is happening across the environment.
Anomaly Detection
Traditional monitoring systems rely on predefined thresholds.
While effective for known conditions, threshold-based monitoring often misses unexpected issues.
AIOps platforms use machine learning models to establish normal operating patterns. The system continuously learns how applications, infrastructure, and services behave under typical conditions.
When performance deviates from these patterns, the platform identifies the activity as an anomaly. This may include unusual traffic spikes, latency increases, resource consumption changes, or application failures.
By detecting abnormal behavior early, AIOps platforms help teams respond before users experience major disruptions.
Automated Remediation
Many operational problems follow predictable patterns.
AIOps platforms can automate responses to these recurring incidents. When specific conditions occur, the platform executes predefined workflows without requiring manual intervention.
For example, an AIOps platform may restart a failed service, create an incident ticket, or trigger a recovery workflow automatically.
Automation reduces response times and helps maintain service availability. It also allows IT teams to spend less time performing repetitive operational tasks.
Predictive Analytics
Modern AIOps platforms do more than react to incidents.
They use predictive analytics to identify potential problems before they affect business operations.
Machine learning models analyze historical and real-time operational data to detect trends associated with future failures. These insights help organizations anticipate capacity shortages, performance degradation, and infrastructure bottlenecks.
Predictive analytics allows operations teams to take corrective action before issues become outages.
As a result, organizations improve reliability, reduce downtime, and adopt a more proactive approach to IT operations management.
Key Features to Look for in AIOps Tools
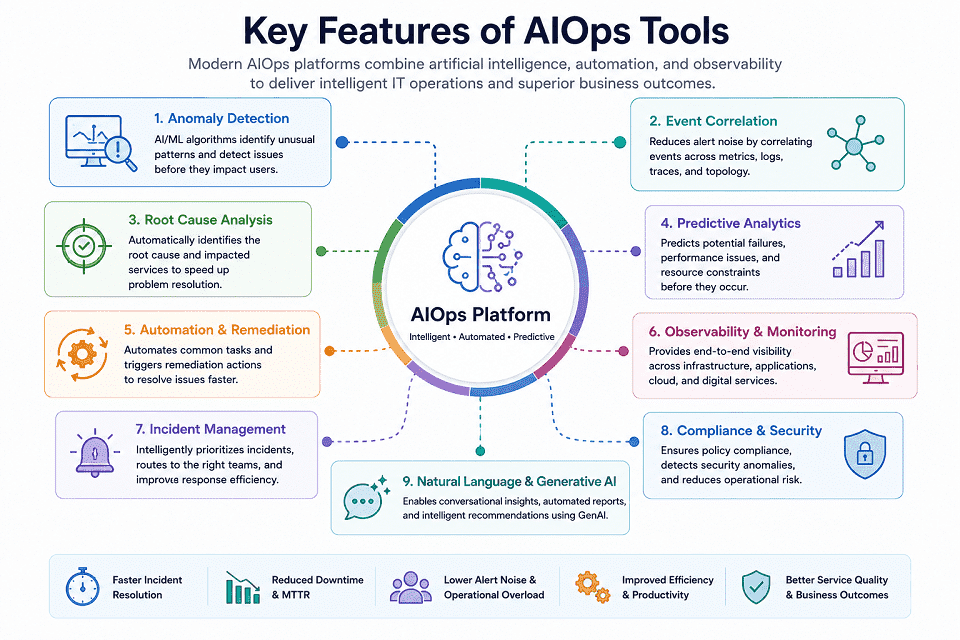 The effectiveness of an AIOps platform depends on its ability to analyze operational data, identify issues quickly, and automate responses across complex IT environments.
The effectiveness of an AIOps platform depends on its ability to analyze operational data, identify issues quickly, and automate responses across complex IT environments.
Not all platforms offer the same capabilities.
Some focus on observability and monitoring, while others emphasize automation, incident management, or predictive analytics.
Before selecting an AIOps solution, organizations should evaluate the features that directly support their operational goals.
AIOps Features Comparison
| Feature | Why It Matters |
| AI-Powered Anomaly Detection | Identifies abnormal behavior before failures occur |
| Root Cause Analysis | Helps teams locate the source of incidents faster |
| Predictive Incident Management | Anticipates issues before users are affected |
| Workflow Automation | Reduces manual operational tasks |
| Cloud and Hybrid Monitoring | Provides visibility across diverse environments |
| ITSM Integration | Connects operations with service management processes |
| Security and Compliance Features | Supports governance, auditing, and risk management |
AI-Powered Anomaly Detection
Anomaly detection is one of the most important capabilities in an AIOps platform.
Traditional monitoring tools rely on fixed thresholds. These thresholds work well for known conditions but often fail to detect unexpected behavior.
AIOps platforms use machine learning to establish normal performance baselines. The system continuously learns how applications, servers, networks, and cloud services behave under typical conditions.
When unusual activity occurs, the platform automatically identifies the deviation and alerts operations teams.
This helps organizations discover issues earlier and reduce the risk of service disruptions.
Root Cause Analysis
Modern IT incidents often affect multiple systems at the same time.
A single infrastructure failure can trigger alerts across applications, databases, networks, and cloud services.
Manually investigating these alerts can be slow and difficult.
AIOps platforms use event correlation and AI models to analyze relationships between incidents. The system identifies the most likely source of the problem and reduces the time required for troubleshooting.
Faster root cause analysis leads to quicker incident resolution and improved service reliability.
Predictive Incident Management
Most monitoring tools focus on detecting problems after they occur.
AIOps platforms go a step further.
Predictive incident management uses machine learning to identify patterns that may indicate future failures. These patterns are based on historical performance data and real-time operational metrics.
For example, the platform may detect growing resource consumption, declining application performance, or storage capacity risks before they become critical.
This proactive approach allows teams to resolve issues before users experience outages.
Workflow Automation
Many operational processes follow predictable workflows.
Tasks such as ticket creation, alert escalation, service restarts, and incident response often consume valuable staff time.
AIOps platforms automate these repetitive activities.
When predefined conditions occur, the platform can execute corrective actions automatically. This reduces response times and improves operational efficiency.
Automation also helps organizations maintain consistent operational processes across large environments.
Cloud and Hybrid Infrastructure Monitoring
Most businesses now operate across multiple infrastructure platforms.
Applications may run in public clouds, private clouds, on-premises data centers, or hybrid environments.
Maintaining visibility across these systems can be challenging.
AIOps platforms provide centralized monitoring across cloud-native and traditional infrastructure. They collect telemetry from multiple sources and present operational insights through a unified platform.
This broader visibility helps teams detect issues that span multiple environments.
ITSM Integration
AIOps platforms become more valuable when integrated with IT Service Management (ITSM) tools.
Integration allows operational events to connect directly with incident management, change management, and service desk workflows.
For example, when an incident occurs, the platform can automatically create tickets, assign ownership, and track resolution progress.
Popular integrations often include ServiceNow, Jira Service Management, and other enterprise ITSM solutions.
These integrations improve coordination between operations teams and service management processes.
Security and Compliance Features
Operational data often plays an important role in security investigations and compliance programs.
Many AIOps platforms include features that support governance, auditing, and regulatory requirements.
These capabilities may include audit logging, role-based access controls, data retention management, and activity tracking.
Security-focused features help organizations maintain visibility into operational changes while supporting compliance frameworks and internal governance policies.
When evaluating AIOps tools, businesses should consider both operational capabilities and governance requirements to ensure the platform supports long-term organizational needs.
Best AIOps Tools in 2026
AIOps platforms have evolved far beyond traditional monitoring tools. Modern solutions combine observability, machine learning, automation, and predictive analytics to help organizations manage increasingly complex IT environments.
The best AIOps tools do more than collect operational data. They analyze patterns across infrastructure, applications, networks, and cloud services to identify issues before they affect users. Many platforms can also automate incident response and reduce the operational burden on IT teams.
The following platforms represent some of the strongest AIOps solutions available in 2026.
Dynatrace
Overview
Dynatrace is an enterprise-grade AIOps platform that combines observability, application performance monitoring, infrastructure analytics, security monitoring, and automation within a unified environment.
The platform is designed to help organizations manage complex cloud-native and hybrid infrastructures. Instead of relying on separate monitoring tools for applications, servers, containers, and cloud services, Dynatrace provides a centralized view of operational health across the entire technology stack.
A major differentiator is its Davis AI engine. The platform continuously analyzes operational data and automatically identifies relationships between applications, services, infrastructure components, and user experiences. This allows teams to detect issues faster and reduce manual troubleshooting efforts.
Today, Dynatrace is widely used by large enterprises that require deep visibility across modern distributed environments.
Best For
Dynatrace is best suited for large enterprises, cloud-native organizations, and businesses operating complex hybrid infrastructures.
It performs particularly well in environments that use Kubernetes, microservices, multi-cloud architectures, and large-scale digital applications.
Organizations seeking a single platform for observability, automation, and AI-driven operations often consider Dynatrace one of the strongest options available.
Key Features
Dynatrace provides full-stack observability across applications, infrastructure, networks, containers, databases, and cloud services.
One of its most valuable capabilities is automatic dependency mapping. The platform continuously discovers relationships between system components and creates a real-time topology of the environment. This helps operations teams understand how changes or failures affect business services.
The platform also includes distributed tracing, digital experience monitoring, infrastructure analytics, cloud automation, and application performance monitoring. These capabilities allow organizations to monitor both technical performance and end-user experience from a single platform.
Unlike traditional monitoring tools that generate large volumes of isolated alerts, Dynatrace focuses on providing contextual insights that help teams understand the root cause of operational issues more quickly.
AI Capabilities
The Davis AI engine is the intelligence layer that powers Dynatrace’s AIOps capabilities. Unlike many platforms that rely heavily on static rules and manual thresholds, Davis AI continuously analyzes operational data in real time.
The platform evaluates logs, metrics, traces, events, and user activity to understand how applications and infrastructure behave under normal conditions. When unusual patterns appear, Davis AI automatically identifies anomalies and investigates potential causes.
One of Dynatrace’s strongest capabilities is automated root cause analysis. Instead of presenting hundreds of separate alerts, the platform correlates related events and identifies the underlying issue responsible for service degradation or outages.
The platform also supports predictive insights by detecting performance trends that may lead to future incidents. This allows operations teams to address problems before users experience disruptions.
As environments become more complex, these AI-driven capabilities help reduce alert fatigue and improve operational efficiency.
Integrations
Dynatrace integrates with a broad range of enterprise technologies and cloud platforms.
The platform supports major cloud providers, including Amazon Web Services, Microsoft Azure, and Google Cloud Platform. It also integrates with Kubernetes, Red Hat OpenShift, VMware, Docker, and other container technologies commonly used in modern cloud environments.
For IT operations and service management, Dynatrace connects with ServiceNow, Jira, PagerDuty, and various incident management platforms.
Development teams can also integrate Dynatrace with CI/CD pipelines, source control systems, and DevOps toolchains to improve application delivery and operational visibility.
These integrations help organizations create a unified monitoring and operations ecosystem.
Pros
- Industry-leading AI-driven root cause analysis
- Excellent full-stack observability capabilities
- Strong support for cloud-native and hybrid environments
Cons
- Premium pricing compared to many competitors
- Advanced features may require a learning curve for new users
Pricing
Dynatrace uses a consumption-based pricing model.
Costs depend on monitored infrastructure, application workloads, observability requirements, and platform usage. Organizations can select services based on their operational needs and scale deployments as environments grow.
Because pricing varies significantly across deployments, most enterprises work directly with Dynatrace to obtain customized pricing estimates.
Expert Verdict
Dynatrace remains one of the most powerful AIOps platforms available in 2026.
Its combination of full-stack observability, advanced automation, and AI-driven root cause analysis makes it particularly valuable for enterprises managing large and complex digital environments.
Organizations seeking deep operational visibility and proactive incident management will find Dynatrace among the strongest choices in the AIOps market.
Datadog
Overview
Datadog is a cloud-native observability and AIOps platform that helps organizations monitor applications, infrastructure, networks, databases, and cloud services from a single interface.
Originally focused on cloud monitoring, Datadog has evolved into a comprehensive operations platform that combines observability, security monitoring, log management, application performance monitoring, and AI-powered operational analytics.
The platform is widely adopted by DevOps teams, Site Reliability Engineers (SREs), and cloud-first organizations because of its flexibility and extensive integration ecosystem.
Unlike many traditional monitoring tools, Datadog was built specifically for modern cloud environments. This makes it particularly effective for organizations running distributed applications, microservices, containers, and hybrid cloud architectures.
Best For
Datadog is best suited for cloud-native businesses, DevOps teams, SaaS companies, and organizations undergoing digital transformation.
It works especially well for businesses that need broad visibility across cloud services, applications, infrastructure, and development workflows without deploying multiple monitoring platforms.
Organizations seeking rapid deployment and strong cloud observability often shortlist Datadog alongside Dynatrace.
Key Features
Datadog provides unified observability across infrastructure, applications, logs, traces, and security events.
The platform allows teams to correlate telemetry from different sources and investigate incidents through a centralized dashboard. This improves operational visibility and reduces troubleshooting time.
One of Datadog’s strongest advantages is its extensive monitoring coverage. Teams can monitor servers, containers, databases, cloud services, APIs, and applications from a single platform.
The platform also includes distributed tracing, network performance monitoring, real-user monitoring, synthetic monitoring, cloud security monitoring, and log analytics.
These capabilities help organizations understand system performance at both the infrastructure and application layers.
AI Capabilities
Datadog uses machine learning to improve anomaly detection, alert management, and operational intelligence.
The platform continuously analyzes telemetry data to establish performance baselines and identify abnormal behavior. When unusual activity occurs, Datadog highlights the issue and provides contextual information that helps teams investigate incidents faster.
Its Watchdog AI engine automatically detects performance anomalies, identifies emerging issues, and surfaces insights that may otherwise go unnoticed.
Datadog also applies machine learning to reduce alert fatigue by prioritizing significant events and suppressing unnecessary notifications.
These capabilities help operations teams focus on incidents that have the greatest business impact.
Integrations
Datadog offers one of the largest integration ecosystems in the observability market.
The platform supports hundreds of integrations across cloud providers, databases, container platforms, networking technologies, collaboration tools, security solutions, and DevOps services.
Popular integrations include AWS, Microsoft Azure, Google Cloud Platform, Kubernetes, Docker, Jenkins, GitHub, ServiceNow, Jira, Slack, PagerDuty, Splunk, and many other enterprise technologies.
This extensive integration support allows organizations to consolidate operational visibility without replacing existing tools.
Pros
- Excellent cloud-native monitoring capabilities
- Extensive integration ecosystem
- Easy deployment and scalability
Cons
- Costs can increase significantly as environments grow
- Advanced features may require additional product modules
Pricing
Datadog uses a modular pricing model based on products and usage.
Organizations can start with core monitoring services and add observability, security, log management, and AIOps capabilities as requirements evolve.
This flexibility makes Datadog accessible to growing businesses, although costs should be monitored carefully as deployments expand.
Expert Verdict
Datadog is one of the most versatile AIOps and observability platforms available in 2026.
Its cloud-native architecture, broad monitoring coverage, AI-powered analytics, and extensive integrations make it an excellent choice for modern IT operations teams.
Organizations prioritizing cloud visibility, operational flexibility, and rapid deployment will find Datadog among the strongest options in the AIOps market.
Splunk ITSI
Overview
Splunk IT Service Intelligence (ITSI) is an enterprise AIOps platform built on top of the Splunk ecosystem. The platform helps organizations monitor service health, reduce alert noise, correlate events, and accelerate incident resolution across complex IT environments.
Unlike infrastructure-focused monitoring tools, Splunk ITSI takes a service-centric approach. Instead of monitoring individual servers or applications in isolation, it focuses on how technology issues affect business services and user experiences.
This approach helps operations teams understand the real business impact of incidents and prioritize response efforts accordingly.
Splunk ITSI is widely used by large enterprises that require visibility across diverse infrastructure, applications, cloud platforms, and operational workflows.
Best For
Splunk ITSI is best suited for large enterprises, highly regulated industries, and organizations managing mission-critical business services.
It is particularly valuable for companies already using Splunk for log analytics, security monitoring, or observability.
Organizations seeking service-centric visibility and operational intelligence often consider Splunk ITSI one of the strongest enterprise AIOps solutions available.
Key Features
The platform combines service health monitoring, event correlation, predictive analytics, incident investigation, and operational intelligence within a unified environment.
One of its most valuable capabilities is service monitoring. Splunk ITSI continuously evaluates the health of business services by analyzing data from multiple operational sources.
The platform also provides customizable dashboards, service dependency mapping, KPI monitoring, and real-time operational analytics.
Its service analyzer enables operations teams to identify performance degradation quickly and understand how infrastructure issues affect business-critical services.
These capabilities help organizations move beyond traditional monitoring and adopt a more business-focused approach to IT operations.
AI Capabilities
Machine learning plays a central role in Splunk ITSI’s AIOps strategy.
The platform continuously analyzes operational data to identify unusual behavior, correlate related events, and reduce alert noise.
Its event analytics engine automatically groups connected alerts into meaningful incidents. This helps teams avoid investigating duplicate notifications and focus on root causes.
Splunk ITSI also supports predictive analytics. The platform can identify patterns that may indicate future service degradation or operational risks before they affect end users.
These capabilities improve incident response efficiency and help organizations reduce downtime.
Integrations
Splunk ITSI integrates naturally with the broader Splunk ecosystem and supports a wide range of enterprise technologies.
The platform connects with cloud providers, infrastructure monitoring tools, observability platforms, security solutions, ITSM systems, and enterprise applications.
Common integrations include AWS, Microsoft Azure, Google Cloud Platform, ServiceNow, Jira, Kubernetes, VMware, and various monitoring and automation tools.
These integrations help organizations centralize operational intelligence across diverse technology environments.
Pros
- Strong service-centric monitoring capabilities
- Advanced event correlation and analytics
- Excellent fit for large enterprise environments
Cons
- Can be complex to deploy and manage
- Higher cost compared to many mid-market solutions
Pricing
Splunk ITSI typically follows enterprise-oriented pricing based on data ingestion, platform usage, and deployment scale.
Costs vary significantly depending on infrastructure size and operational requirements.
Organizations generally work directly with Splunk to obtain customized pricing estimates.
Expert Verdict
Splunk ITSI is one of the strongest enterprise AIOps platforms available in 2026.
Its service-centric approach, machine learning capabilities, and operational intelligence features make it particularly valuable for organizations managing large-scale digital services.
Enterprises seeking deeper visibility into service health and business impact analysis should place Splunk ITSI high on their evaluation list.
New Relic
Overview
New Relic is a cloud-based observability and AIOps platform that helps organizations monitor applications, infrastructure, networks, databases, and user experiences from a unified platform.
The company originally gained recognition for application performance monitoring (APM), but it has evolved into a comprehensive observability solution with strong AIOps capabilities. Today, New Relic provides visibility across modern cloud-native environments, helping operations teams identify issues, improve performance, and accelerate incident resolution.
One of the platform’s biggest strengths is its ability to unify telemetry data from multiple sources. By combining logs, metrics, traces, and events within a single environment, New Relic helps teams understand how different parts of an application ecosystem interact.
Best For
New Relic is best suited for cloud-native organizations, software development teams, DevOps teams, and SaaS businesses.
It is particularly valuable for companies that prioritize application performance, customer experience, and operational visibility across distributed environments.
Organizations looking for a balance between observability, AIOps, and ease of adoption often find New Relic an attractive option.
Key Features
New Relic provides application performance monitoring, infrastructure monitoring, distributed tracing, log management, synthetic monitoring, and real-user monitoring.
The platform’s unified telemetry architecture allows teams to analyze operational data from multiple sources without switching between tools.
Its observability capabilities help organizations identify performance bottlenecks, troubleshoot incidents, and optimize application reliability.
New Relic also provides customizable dashboards, service maps, dependency visualization, and advanced analytics that improve operational decision-making.
These features make it easier for teams to maintain visibility across increasingly complex cloud environments.
AI Capabilities
New Relic incorporates machine learning to enhance anomaly detection, alert management, and operational intelligence.
The platform continuously analyzes telemetry data to establish normal performance patterns and identify unusual behavior. When anomalies occur, New Relic highlights the issue and provides contextual insights that assist with troubleshooting.
Its intelligent alerting capabilities help reduce alert fatigue by filtering unnecessary notifications and prioritizing incidents that require immediate attention.
Machine learning also supports faster root cause analysis by identifying relationships between performance events and operational changes.
Integrations
New Relic integrates with hundreds of technologies across cloud computing, containers, databases, CI/CD pipelines, collaboration tools, and DevOps ecosystems.
Popular integrations include AWS, Microsoft Azure, Google Cloud Platform, Kubernetes, Docker, GitHub, Jenkins, ServiceNow, Jira, Slack, and PagerDuty.
These integrations allow organizations to centralize operational visibility while continuing to use their existing technology stack.
Pros
- Strong application performance monitoring capabilities
- Unified observability across multiple telemetry sources
- Flexible deployment and pricing options
Cons
- Advanced analytics can require configuration effort
- Large environments may generate significant data costs
Pricing
New Relic uses a consumption-based pricing model that allows organizations to scale usage according to operational requirements.
Businesses can start with core observability services and expand into advanced monitoring, analytics, and AIOps capabilities as their needs evolve.
This flexibility makes New Relic suitable for both growing companies and large enterprises.
Expert Verdict
New Relic is one of the most balanced observability and AIOps platforms available in 2026.
Its combination of application monitoring, operational analytics, and machine learning-powered insights makes it a strong choice for organizations seeking visibility across modern cloud environments.
For teams focused on application reliability, customer experience, and operational efficiency, New Relic remains a highly competitive option.
LogicMonitor
Overview
LogicMonitor is a cloud-based infrastructure monitoring and AIOps platform designed to help organizations manage modern hybrid IT environments. The platform provides visibility across on-premises infrastructure, cloud services, applications, networks, and storage systems through a single operational interface.
Unlike some AIOps platforms that focus primarily on application observability, LogicMonitor places strong emphasis on infrastructure monitoring and operational simplicity. Its automated discovery capabilities help organizations gain visibility into complex environments without lengthy deployment projects.
The platform has become particularly popular among enterprises, managed service providers (MSPs), and organizations operating hybrid infrastructures.
Best For
LogicMonitor is best suited for mid-sized enterprises, large organizations managing hybrid environments, and managed service providers supporting multiple customers.
It is an excellent choice for businesses seeking enterprise-grade monitoring and AIOps capabilities without the complexity often associated with larger enterprise platforms.
Organizations looking for rapid deployment and broad infrastructure visibility frequently consider LogicMonitor.
Key Features
LogicMonitor provides infrastructure monitoring, network performance monitoring, cloud observability, application monitoring, topology mapping, and dependency analysis.
One of its most valuable features is automated discovery. The platform automatically identifies devices, applications, cloud resources, and infrastructure components across the environment. This reduces manual configuration and accelerates deployment.
The platform also offers customizable dashboards, service monitoring, capacity planning, and operational analytics. These capabilities help IT teams maintain visibility across both traditional and cloud-based infrastructure.
LogicMonitor’s unified monitoring approach enables organizations to monitor diverse technology environments from a single platform rather than relying on multiple disconnected tools.
AI Capabilities
LogicMonitor incorporates machine learning to improve anomaly detection, event correlation, and operational intelligence.
The platform continuously analyzes performance patterns and identifies unusual behavior that may indicate service degradation or infrastructure issues. Machine learning models help reduce alert noise by filtering redundant notifications and highlighting incidents that require attention.
LogicMonitor also provides predictive insights that help organizations anticipate capacity constraints, performance bottlenecks, and operational risks before they become critical problems.
These capabilities allow operations teams to adopt a more proactive approach to infrastructure management.
Integrations
LogicMonitor integrates with major cloud providers, virtualization platforms, networking technologies, ITSM tools, and collaboration platforms.
Popular integrations include AWS, Microsoft Azure, Google Cloud Platform, VMware, Kubernetes, ServiceNow, Jira, Slack, and Microsoft Teams.
The platform also supports integration with numerous infrastructure technologies, making it suitable for organizations operating diverse technology stacks.
Pros
- Strong hybrid infrastructure monitoring
- Automated discovery and deployment
- Good balance between monitoring and AIOps capabilities
Cons
- Application observability is less advanced than some competitors
- Advanced customization may require additional configuration
Pricing
LogicMonitor uses subscription-based pricing that varies according to monitored resources and deployment requirements.
Organizations can scale monitoring coverage as infrastructure grows, making the platform suitable for both expanding businesses and large enterprises.
Expert Verdict
LogicMonitor is one of the strongest AIOps platforms for organizations managing hybrid infrastructure environments.
Its combination of infrastructure visibility, operational intelligence, and deployment simplicity makes it particularly attractive for enterprises and managed service providers.
Businesses seeking practical AIOps capabilities without excessive complexity should place LogicMonitor high on their shortlist.
PagerDuty AIOps
Overview
PagerDuty AIOps is an incident management and operational intelligence platform designed to help organizations detect, prioritize, and resolve incidents faster. While many AIOps platforms focus on infrastructure monitoring and observability, PagerDuty focuses on event intelligence, alert correlation, and automated incident response.
The platform acts as a central coordination layer between monitoring systems, observability tools, IT service management platforms, and operations teams.
As modern environments generate thousands of alerts daily, PagerDuty helps organizations reduce operational noise and ensure critical incidents receive immediate attention.
Best For
PagerDuty AIOps is best suited for Site Reliability Engineering (SRE) teams, DevOps teams, cloud operations teams, and organizations managing large-scale digital services.
It is particularly valuable for businesses struggling with alert fatigue, slow incident response, and fragmented operational workflows.
Organizations seeking to improve operational coordination often choose PagerDuty as a core component of their AIOps strategy.
Key Features
PagerDuty automatically ingests alerts from multiple monitoring and observability platforms. The platform then correlates related events and groups them into meaningful incidents.
This approach helps reduce duplicate alerts and prevents operations teams from becoming overwhelmed by excessive notifications.
The platform also provides automated escalation policies, on-call scheduling, incident response workflows, service dependency awareness, and operational dashboards.
Its centralized incident management capabilities improve collaboration across operations, engineering, and support teams during critical events.
AI Capabilities
Machine learning powers PagerDuty’s event intelligence capabilities.
The platform continuously analyzes operational data to identify patterns, suppress duplicate alerts, and prioritize incidents based on urgency and business impact.
Its intelligent event correlation engine helps teams focus on the incidents most likely to affect services and customers.
PagerDuty also learns from historical incident data to improve alert classification and response efficiency over time.
These capabilities reduce alert fatigue and help organizations accelerate incident resolution.
Integrations
PagerDuty offers one of the largest integration ecosystems in the AIOps and incident management market.
The platform integrates with Datadog, Dynatrace, Splunk, New Relic, AWS, Microsoft Azure, Google Cloud Platform, ServiceNow, Jira, Slack, Microsoft Teams, Kubernetes, and hundreds of other operational technologies.
These integrations allow organizations to centralize incident response without replacing existing monitoring investments.
Pros
- Excellent incident response automation
- Strong event correlation and alert intelligence
- Extensive third-party integration support
Cons
- Limited infrastructure monitoring capabilities
- Most effective when combined with observability platforms
Pricing
PagerDuty offers multiple subscription tiers based on operational requirements and feature availability.
Organizations can begin with core incident management capabilities and expand into advanced AIOps, automation, and event intelligence features as operational needs grow.
Expert Verdict
PagerDuty AIOps is one of the best platforms for incident management and operational response automation.
Organizations dealing with alert overload, operational complexity, and incident coordination challenges will benefit greatly from its intelligent event management capabilities.
While it is not a replacement for full observability platforms, it serves as an excellent operational command center for modern IT teams.
BigPanda
Overview
BigPanda is an enterprise-focused AIOps platform built to help organizations reduce alert overload and improve incident management. The platform specializes in event correlation, operational intelligence, and incident prioritization across large and complex IT environments.
Modern enterprises often use dozens of monitoring and observability tools. While these tools generate valuable data, they can also produce thousands of alerts every day. BigPanda addresses this challenge by consolidating operational signals into a unified incident management layer.
Its primary goal is to help operations teams identify the incidents that matter most while reducing time spent investigating duplicate alerts.
Best For
BigPanda is best suited for large enterprises operating hybrid, multi-cloud, and distributed environments.
It is particularly valuable for organizations that use multiple monitoring platforms and struggle with alert fatigue, fragmented visibility, and slow incident resolution.
Businesses seeking centralized event intelligence often consider BigPanda alongside PagerDuty and Splunk ITSI.
Key Features
The platform collects alerts, events, and telemetry from a wide range of monitoring and observability systems. It then correlates related signals into a single operational incident.
This approach significantly reduces alert noise and provides teams with a clearer understanding of ongoing issues.
BigPanda also offers incident prioritization, topology awareness, service dependency mapping, root cause identification, and operational dashboards.
These capabilities help operations teams understand how infrastructure problems affect business services and customer experiences.
AI Capabilities
Artificial intelligence is at the core of BigPanda’s platform.
Machine learning models continuously analyze operational data to identify relationships between alerts, applications, services, and infrastructure components.
The platform automatically groups related events and determines the most likely root cause of an incident. This reduces manual investigation effort and accelerates troubleshooting.
BigPanda also prioritizes incidents according to operational impact, helping teams focus on the issues most likely to affect service availability.
As environments grow more complex, these AI-driven capabilities become increasingly valuable.
Integrations
BigPanda integrates with a wide range of enterprise monitoring, observability, cloud, and IT service management platforms.
Popular integrations include Datadog, Dynatrace, New Relic, Splunk, ServiceNow, AWS, Microsoft Azure, Google Cloud Platform, Jira, and numerous infrastructure monitoring solutions.
These integrations allow organizations to preserve existing monitoring investments while adding an intelligent operational layer above them.
Pros
- Industry-leading event correlation capabilities
- Excellent alert noise reduction
- Strong support for large enterprise environments
Cons
- Focused primarily on incident intelligence rather than observability
- Enterprise pricing may not suit smaller organizations
Pricing
BigPanda provides customized pricing based on deployment size, operational complexity, and business requirements.
Organizations typically work directly with the vendor to determine licensing costs and implementation scope.
Expert Verdict
BigPanda is one of the strongest AIOps platforms for organizations overwhelmed by operational alerts.
Its AI-driven event correlation, incident intelligence, and root cause analysis capabilities make it particularly valuable for large enterprises managing complex IT environments.
Businesses seeking to reduce alert fatigue and improve operational efficiency should place BigPanda high on their shortlist.
Moogsoft
Overview
Moogsoft is one of the pioneers of the AIOps market and helped define many of the concepts used by modern operational intelligence platforms. The platform focuses on event correlation, anomaly detection, noise reduction, and incident management.
As IT environments become more distributed, operations teams often struggle to distinguish critical incidents from routine alerts. Moogsoft addresses this challenge by applying machine learning to operational data and helping teams focus on issues that require immediate attention.
The platform is designed to improve operational efficiency while reducing the manual effort associated with monitoring and troubleshooting.
Best For
Moogsoft is best suited for large enterprises, network operations centers (NOCs), and IT operations teams managing complex infrastructure environments.
It is particularly valuable for organizations seeking to reduce alert fatigue and improve operational visibility across multiple monitoring systems.
Businesses looking for mature event intelligence capabilities often consider Moogsoft among the leading AIOps platforms.
Key Features
Moogsoft combines anomaly detection, event correlation, incident clustering, topology awareness, and operational analytics within a unified platform.
One of its strongest capabilities is noise reduction. The platform continuously analyzes incoming alerts and automatically groups related events into meaningful incidents.
This process helps teams avoid investigating hundreds of duplicate alerts generated from a single underlying issue.
Moogsoft also provides operational dashboards, incident workflows, service visibility, and collaboration tools that support faster troubleshooting and decision-making.
AI Capabilities
Machine learning forms the foundation of Moogsoft’s operational intelligence engine.
The platform continuously learns from infrastructure behavior, operational events, and historical incidents. It uses this information to identify unusual activity, detect emerging problems, and correlate related alerts.
Its AI-driven incident clustering capabilities help operations teams understand the broader context surrounding outages and performance issues.
By identifying patterns across multiple systems, Moogsoft helps teams accelerate root cause analysis and reduce mean time to resolution (MTTR).
Integrations
Moogsoft integrates with monitoring platforms, observability tools, cloud services, ITSM systems, collaboration platforms, and enterprise infrastructure technologies.
Common integrations include Splunk, Datadog, Dynatrace, ServiceNow, AWS, Microsoft Azure, Google Cloud Platform, Jira, Slack, and various network monitoring solutions.
These integrations allow organizations to centralize operational intelligence without replacing existing monitoring tools.
Pros
- Strong event correlation and incident clustering
- Effective alert noise reduction
- Mature AIOps platform with proven enterprise adoption
Cons
- Smaller ecosystem than some leading competitors
- Enterprise-focused deployment may be excessive for smaller teams
Pricing
Moogsoft offers customized pricing based on deployment size, operational requirements, and platform usage.
Organizations typically work directly with the vendor to determine licensing and implementation costs.
Expert Verdict
Moogsoft remains one of the most respected names in the AIOps market.
Its strengths in anomaly detection, event intelligence, and incident clustering make it a strong choice for enterprises seeking to reduce alert fatigue and improve operational efficiency.
Organizations operating large-scale environments should consider Moogsoft when evaluating mature AIOps solutions.
IBM Cloud Pak for AIOps
Overview
IBM Cloud Pak for AIOps is an enterprise-grade AIOps platform designed to help organizations automate IT operations, improve service reliability, and manage increasingly complex hybrid cloud environments.
The platform combines artificial intelligence, machine learning, observability, event management, and automation within a unified operational framework. IBM developed the solution to help enterprises move from reactive operations to proactive and predictive operations management.
Unlike many AIOps platforms that focus primarily on monitoring, IBM Cloud Pak for AIOps places strong emphasis on automation and operational resilience.
Best For
IBM Cloud Pak for AIOps is best suited for large enterprises managing hybrid cloud infrastructure, mission-critical applications, and complex digital services.
It is particularly valuable for organizations pursuing large-scale digital transformation initiatives or operating in highly regulated environments where uptime and operational reliability are critical.
Companies already using IBM technologies often benefit from tighter integration and streamlined deployment.
Key Features
The platform provides observability, event correlation, topology mapping, service dependency analysis, incident management, and workflow automation.
One of its most valuable capabilities is topology awareness. IBM Cloud Pak for AIOps continuously maps relationships between applications, infrastructure, services, and business processes. This helps operations teams understand how technical issues affect business outcomes.
The platform also supports automated remediation workflows, service health monitoring, change risk analysis, and operational dashboards that provide real-time visibility into IT environments.
These capabilities help organizations reduce downtime and improve operational efficiency.
AI Capabilities
Artificial intelligence sits at the center of IBM’s AIOps strategy.
The platform continuously analyzes logs, metrics, traces, events, and operational data from across the environment. Machine learning models identify anomalies, detect emerging issues, and correlate related incidents automatically.
IBM Cloud Pak for AIOps also supports predictive analytics that help operations teams identify risks before they impact users.
One of its strongest capabilities is intelligent automation. The platform can recommend corrective actions and automate remediation workflows based on historical operational patterns.
This reduces manual intervention and accelerates incident resolution.
Integrations
IBM Cloud Pak for AIOps integrates with a wide range of enterprise technologies and cloud platforms.
Key integrations include Red Hat OpenShift, Kubernetes, AWS, Microsoft Azure, Google Cloud Platform, ServiceNow, Instana, Turbonomic, and numerous monitoring and observability solutions.
These integrations allow organizations to consolidate operational intelligence across hybrid and multi-cloud environments.
Pros
- Comprehensive enterprise AIOps platform
- Strong automation and remediation capabilities
- Excellent support for hybrid cloud environments
Cons
- Complex implementation for smaller organizations
- Enterprise pricing may exceed mid-market budgets
Pricing
IBM provides customized pricing based on deployment scale, infrastructure complexity, and operational requirements.
Large enterprise environments typically require tailored licensing and implementation plans.
Organizations should contact IBM directly for detailed pricing information.
Expert Verdict
IBM Cloud Pak for AIOps is one of the most comprehensive enterprise AIOps solutions available in 2026.
Its combination of AI-driven analytics, automation, observability, and operational resilience makes it an excellent choice for large organizations managing complex hybrid cloud environments.
Enterprises seeking advanced automation and proactive operations management should place IBM Cloud Pak for AIOps among their top contenders.
ScienceLogic
Overview
ScienceLogic is a hybrid-cloud monitoring and AIOps platform that helps organizations manage infrastructure, applications, networks, cloud services, and business services from a unified operational environment.
The platform combines observability, service monitoring, dependency mapping, automation, and operational analytics to provide end-to-end visibility across modern IT environments.
Unlike many monitoring solutions that focus primarily on infrastructure metrics, ScienceLogic emphasizes service-centric operations. This allows organizations to understand how technology performance affects business outcomes.
The platform is widely used by enterprises, managed service providers (MSPs), and organizations operating large hybrid infrastructures.
Best For
ScienceLogic is best suited for enterprises managing hybrid cloud environments, service providers supporting multiple customers, and organizations seeking service-level visibility across complex infrastructures.
It is particularly valuable for businesses that need to monitor both traditional data center resources and cloud-native environments through a single platform.
Organizations looking for strong operational visibility and service dependency awareness often consider ScienceLogic among their leading AIOps options.
Key Features
ScienceLogic provides infrastructure monitoring, application monitoring, service monitoring, topology mapping, dependency analysis, event correlation, and workflow automation.
One of its most valuable capabilities is dynamic dependency mapping. The platform continuously discovers relationships between applications, servers, cloud resources, network devices, and business services.
This visibility helps operations teams understand how incidents propagate across the environment and which services are affected.
The platform also includes operational dashboards, capacity planning, service health monitoring, and automated workflows that simplify IT operations management.
AI Capabilities
ScienceLogic uses machine learning and operational analytics to improve incident detection, event correlation, and operational efficiency.
The platform continuously analyzes operational data to identify abnormal behavior and prioritize incidents based on service impact.
Its AIOps capabilities help reduce alert noise by grouping related events and highlighting the most important operational issues.
ScienceLogic also supports predictive insights that help organizations anticipate performance bottlenecks, capacity constraints, and infrastructure risks before they become critical problems.
These capabilities allow operations teams to adopt a more proactive approach to service management.
Integrations
ScienceLogic integrates with major cloud providers, virtualization platforms, IT service management solutions, collaboration tools, and enterprise applications.
Popular integrations include AWS, Microsoft Azure, Google Cloud Platform, VMware, ServiceNow, Jira, Microsoft Teams, Slack, Kubernetes, and numerous monitoring technologies.
These integrations help organizations centralize operational visibility while preserving existing technology investments.
Pros
- Strong hybrid cloud monitoring capabilities
- Excellent service dependency visibility
- Good balance of monitoring and automation features
Cons
- Interface may require training for new users
- Best suited for mid-sized and large organizations
Pricing
ScienceLogic offers customized pricing based on deployment scope, monitored assets, and operational requirements.
Organizations typically work directly with the vendor to determine licensing costs and implementation plans.
Expert Verdict
ScienceLogic is a mature and capable AIOps platform that combines monitoring, observability, automation, and service intelligence within a unified environment.
Its strengths in hybrid infrastructure monitoring and service dependency analysis make it particularly attractive for enterprises and managed service providers.
Organizations seeking operational visibility across complex IT environments should consider ScienceLogic a strong contender in the AIOps market.
AIOps Tools Comparison Table
Choosing the right AIOps platform depends on your infrastructure, operational maturity, automation requirements, and business goals. Some platforms focus on observability, while others specialize in incident intelligence, event correlation, or operational automation.
The following comparison highlights the strengths of the leading AIOps tools in 2026.
| Platform | Best For | Primary Strength | AI Capabilities | Deployment Focus |
| Dynatrace | Large enterprises | Full-stack observability | Advanced root cause analysis | Hybrid and multi-cloud |
| Datadog | Cloud-native organizations | Unified observability | Anomaly detection and alert intelligence | Cloud-first environments |
| Splunk ITSI | Enterprise IT operations | Service intelligence | Predictive analytics and event correlation | Hybrid environments |
| New Relic | DevOps and engineering teams | Application observability | Intelligent alerting and anomaly detection | Cloud-native environments |
| LogicMonitor | Mid-sized enterprises and MSPs | Infrastructure monitoring | Event correlation and predictive insights | Hybrid infrastructure |
| PagerDuty AIOps | Incident response teams | Incident automation | Event intelligence and alert prioritization | Multi-platform environments |
| BigPanda | Large enterprises | Event correlation | Incident intelligence and root cause analysis | Hybrid and multi-cloud |
| Moogsoft | Operations centers | Event management | Anomaly detection and incident clustering | Enterprise infrastructure |
| IBM Cloud Pak for AIOps | Large enterprises | Automation and resilience | Predictive analytics and remediation | Hybrid cloud environments |
| ScienceLogic | Enterprises and MSPs | Service visibility | Incident prioritization and predictive insights | Hybrid infrastructure |
Best AIOps Tools by Use Case
Different organizations have different operational priorities. The best platform often depends on the specific challenges a business wants to solve.
| Use Case | Recommended Tool |
| Best Overall AIOps Platform | Dynatrace |
| Best for Cloud-Native Teams | Datadog |
| Best for Enterprise Service Intelligence | Splunk ITSI |
| Best for Application Observability | New Relic |
| Best for Hybrid Infrastructure Monitoring | LogicMonitor |
| Best for Incident Response Automation | PagerDuty AIOps |
| Best for Alert Correlation | BigPanda |
| Best for Event Intelligence | Moogsoft |
| Best for Large Enterprise Automation | IBM Cloud Pak for AIOps |
| Best for Managed Service Providers | ScienceLogic |
Which AIOps Platform Is Best?
There is no universal AIOps platform that fits every organization.
Dynatrace offers some of the most advanced AI-driven observability capabilities available today. Datadog remains a strong choice for cloud-native environments, while Splunk ITSI excels in service-centric monitoring and operational intelligence.
Organizations focused on incident management often prefer PagerDuty AIOps. Businesses dealing with excessive alert volumes may benefit from BigPanda or Moogsoft. Enterprises managing large hybrid cloud environments frequently evaluate IBM Cloud Pak for AIOps, LogicMonitor, and ScienceLogic.
The right choice depends on infrastructure complexity, operational goals, budget, existing technology investments, and automation requirements.
Before selecting an AIOps platform, organizations should evaluate deployment requirements, integration capabilities, scalability, and long-term operational value rather than focusing solely on feature lists.
AIOps vs Traditional IT Monitoring Tools
AIOps and traditional IT monitoring tools both help organizations monitor infrastructure and applications. However, they differ significantly in how they collect, analyze, and act on operational data.
Traditional monitoring platforms focus on visibility and alert generation. AIOps platforms go further by applying artificial intelligence, machine learning, and automation to help teams understand and resolve issues faster.
As IT environments become more distributed and cloud-driven, many organizations are moving from reactive monitoring to intelligent operations management.
Alert Management
Traditional monitoring tools generate alerts when predefined thresholds are exceeded. For example, a system may trigger an alert when CPU utilization exceeds 90% or when application response times rise above a specified limit.
This approach works well for known conditions but often produces large volumes of notifications.
As environments grow, operations teams can experience alert fatigue. Multiple systems may generate separate alerts for the same incident, making it difficult to identify the underlying problem.
AIOps platforms address this challenge through event correlation and intelligent alert management.
Instead of treating every alert as an independent event, AIOps platforms analyze relationships between alerts and group related events into a single incident. This reduces operational noise and helps teams focus on issues that require immediate attention.
Root Cause Analysis
Root cause analysis is one of the biggest differences between traditional monitoring and AIOps.
Traditional monitoring tools typically identify symptoms. They can indicate that a server is overloaded, an application is slow, or a database is unavailable. However, operations teams often must investigate multiple systems manually to determine the actual cause.
AIOps platforms automate much of this process.
By analyzing logs, metrics, traces, events, and service dependencies, AI models can identify relationships between incidents and determine probable root causes.
This capability significantly reduces troubleshooting time and improves incident response efficiency.
Automation Capabilities
Traditional monitoring platforms primarily focus on detection and notification.
Once an alert is generated, operations teams usually perform investigation and remediation manually.
This approach increases response times and places additional workload on IT staff.
AIOps platforms introduce intelligent automation into operational workflows.
Many solutions can automatically create incident tickets, trigger workflows, restart failed services, execute remediation scripts, and escalate incidents without human intervention.
Automation reduces repetitive operational tasks and allows teams to focus on strategic initiatives.
Scalability
Traditional monitoring systems often perform well in smaller environments.
However, as organizations adopt cloud-native architectures, microservices, containers, and hybrid cloud deployments, monitoring complexity increases significantly.
A single business application may involve hundreds of interconnected services and infrastructure components.
Managing these environments manually becomes increasingly difficult.
AIOps platforms are designed to operate at a large scale. Machine learning algorithms continuously process massive volumes of telemetry data and identify meaningful patterns across complex infrastructures.
This scalability allows organizations to maintain operational visibility even as environments continue to grow.
Operational Efficiency
Traditional monitoring provides valuable visibility, but operational teams often spend significant time reviewing alerts, investigating incidents, and correlating information from multiple tools.
This reactive approach can slow incident resolution and increase operational costs.
AIOps improves operational efficiency by automating data analysis, incident prioritization, and operational workflows.
Instead of manually reviewing thousands of alerts, teams receive contextual insights that highlight the most important issues.
This allows operations staff to resolve incidents faster while reducing overall workload.
Predictive Capabilities
Traditional monitoring tools primarily react to existing conditions.
They identify problems after predefined thresholds have been crossed.
While effective for detecting active issues, they provide limited insight into future risks.
AIOps platforms use predictive analytics to identify trends that may lead to future failures.
Machine learning models analyze historical and real-time operational data to forecast capacity constraints, performance degradation, and service disruptions.
This enables organizations to take preventive action before users are affected.
Business Impact Awareness
Most traditional monitoring platforms focus on infrastructure components such as servers, databases, and network devices.
They often provide limited visibility into how technical issues affect business services.
AIOps platforms take a broader approach.
Many solutions incorporate service dependency mapping and business service monitoring. This allows organizations to understand which applications, customers, or business processes are affected by an incident.
As a result, teams can prioritize incidents based on business impact rather than technical severity alone.
AIOps vs Traditional IT Monitoring Comparison Table
| Feature | Traditional IT Monitoring | AIOps |
| Alert Management | Threshold-based alerts | AI-driven event correlation |
| Root Cause Analysis | Mostly manual | Automated and AI-assisted |
| Incident Response | Reactive | Proactive and automated |
| Automation | Limited | Extensive workflow automation |
| Scalability | Moderate | Designed for large-scale environments |
| Predictive Analytics | Minimal | Advanced forecasting capabilities |
| Business Context | Limited | Service-aware intelligence |
| Operational Efficiency | Manual effort required | AI-assisted decision making |
Which Approach Is Better?
Traditional monitoring tools remain valuable for collecting operational data and providing infrastructure visibility.
However, modern IT environments generate far more data than human teams can effectively analyze on their own.
AIOps builds on traditional monitoring by adding intelligence, automation, and predictive capabilities. Organizations operating cloud-native, hybrid, or large-scale environments often find that AIOps improves operational efficiency, reduces downtime, and accelerates incident resolution.
For most enterprises in 2026, AIOps is not replacing monitoring. Instead, it is becoming the intelligence layer that transforms monitoring data into actionable operational insights.
AIOps vs Observability Platforms
AIOps and observability are closely related, but they are not the same thing.
Observability platforms help organizations collect and analyze operational data. AIOps platforms use that data to automate analysis, identify issues, and improve operational decision-making.
In many modern IT environments, observability and AIOps work together rather than compete with each other.
Understanding the differences helps organizations choose the right operational strategy.
What Is Observability?
Observability is the ability to understand the internal state of a system by analyzing its outputs.
Modern observability platforms collect and correlate three primary types of telemetry data:
- logs,
- metrics,
These data sources help operations teams understand how applications, infrastructure, and services behave in real time.
Observability platforms provide visibility into system performance, application health, user experience, and infrastructure operations.
For example, if an application slows down, an observability platform can help teams identify where latency occurs and which services are affected.
Popular observability platforms include Dynatrace, Datadog, New Relic, Splunk Observability Cloud, and Grafana.
Their primary goal is to help teams understand what is happening within complex systems.
Where AIOps and Observability Overlap
AIOps and observability share many common capabilities.
Both technologies collect telemetry data from applications, infrastructure, cloud services, networks, and databases.
Both help organizations monitor operational health and identify performance issues.
Many modern platforms now combine observability and AIOps capabilities within a single solution.
For example, observability platforms often include anomaly detection, intelligent alerting, and event correlation features. Similarly, AIOps platforms depend heavily on observability data to generate insights and automate operational workflows.
Without high-quality observability data, AIOps systems cannot function effectively.
This is why many organizations view observability as the foundation and AIOps as the intelligence layer built on top of that foundation.
Key Differences Between AIOps and Observability
Although the two technologies overlap, their primary objectives differ.
Observability focuses on visibility and understanding.
AIOps focuses on intelligence and action.
Observability platforms help teams investigate incidents by providing access to logs, metrics, traces, dashboards, and performance data.
AIOps platforms go further by automatically analyzing that data and recommending or executing corrective actions.
The difference becomes clear during incident response.
An observability platform may show that an application is experiencing high latency and identify the affected services.
An AIOps platform can analyze the same data, determine the probable root cause, prioritize the incident, and trigger remediation workflows automatically.
| Capability | Observability Platforms | AIOps Platforms |
| Primary Goal | Visibility and understanding | Intelligence and automation |
| Core Data Sources | Logs, metrics, traces | Observability data plus AI analytics |
| Incident Investigation | Human-driven | AI-assisted |
| Root Cause Analysis | Mostly manual | Automated and predictive |
| Alert Management | Monitoring-focused | Event correlation and prioritization |
| Automation | Limited | Extensive |
| Predictive Analytics | Basic to moderate | Advanced |
| Operational Decision Making | Human-led | AI-assisted |
Which One Should Businesses Choose?
The answer depends on organizational needs and operational maturity.
Organizations seeking better visibility into applications, infrastructure, and cloud environments should begin with observability.
Without reliable telemetry data, it is difficult to monitor performance or troubleshoot incidents effectively.
Businesses managing large-scale, hybrid, or cloud-native environments often benefit from adding AIOps capabilities on top of observability platforms.
AIOps helps reduce alert fatigue, accelerate root cause analysis, automate workflows, and improve operational efficiency.
For most enterprises in 2026, the choice is not AIOps or observability.
The strongest operational strategies combine both.
Observability provides the data and visibility needed to understand system behavior. AIOps transforms that data into actionable intelligence that helps teams operate faster and more efficiently.
Organizations looking to modernize IT operations should view observability as the foundation and AIOps as the next stage of operational maturity.
Benefits of Using AIOps Tools
Modern IT environments generate massive amounts of operational data every day. As infrastructure becomes more distributed, traditional monitoring approaches often struggle to keep pace.
AIOps platforms help organizations manage this complexity by combining artificial intelligence, machine learning, and automation with operational workflows.
The result is faster decision-making, improved operational efficiency, and greater service reliability.
Reduced Downtime
Downtime can disrupt business operations, reduce productivity, and affect customer satisfaction.
Traditional monitoring tools often identify problems only after services begin to fail. Operations teams must then investigate alerts, determine the root cause, and manually implement corrective actions.
AIOps platforms help reduce downtime by identifying issues earlier and accelerating incident resolution.
Machine learning models continuously analyze operational data and detect abnormal behavior before it develops into a major outage.
By shortening the time required to identify and resolve problems, organizations can significantly improve service availability.
Faster Incident Response
Responding quickly to incidents is critical in modern IT environments.
Traditional operations teams often spend valuable time reviewing alerts, collecting diagnostic information, and determining which systems are affected.
AIOps platforms streamline this process.
By correlating related events and identifying probable root causes automatically, the platform provides operations teams with actionable insights immediately.
Many solutions also automate incident escalation, ticket creation, and response workflows.
These capabilities reduce mean time to detect (MTTD) and mean time to resolve (MTTR), allowing teams to restore services faster.
Proactive Issue Detection
Most traditional monitoring tools are reactive.
They generate alerts when predefined thresholds are exceeded or when failures have already occurred.
AIOps introduces a more proactive approach.
Machine learning models establish performance baselines and continuously evaluate operational behavior against those baselines.
When unusual patterns emerge, the platform identifies anomalies and highlights potential risks before users experience disruptions.
This allows operations teams to address performance issues, capacity constraints, and infrastructure bottlenecks before they become service-impacting incidents.
Lower Operational Costs
Managing complex IT environments often requires significant operational effort.
Teams spend countless hours investigating alerts, troubleshooting issues, and performing repetitive administrative tasks.
AIOps reduces these manual workloads through automation and intelligent analytics.
Routine operational activities such as incident classification, alert prioritization, ticket creation, and remediation workflows can be automated.
This allows organizations to use existing resources more efficiently and reduce the operational costs associated with managing large-scale environments.
Over time, improved efficiency can lead to substantial cost savings.
Improved Service Reliability
Service reliability is one of the most important objectives of modern IT operations.
Users expect applications, services, and digital platforms to remain available and perform consistently.
AIOps platforms improve reliability by providing continuous visibility into operational health and identifying issues before they affect users.
Automated analysis, predictive insights, and intelligent incident management help organizations maintain stable service delivery even as environments become more complex.
The result is fewer service disruptions, improved customer experiences, and stronger business continuity.
Summary of AIOps Benefits
| Benefit | Business Impact |
| Reduced Downtime | Improves service availability and business continuity |
| Faster Incident Response | Accelerates problem resolution and reduces disruption |
| Proactive Issue Detection | Prevents incidents before users are affected |
| Lower Operational Costs | Reduces manual effort and improves resource utilization |
| Improved Service Reliability | Delivers more consistent application and infrastructure performance |
As organizations continue adopting cloud-native architectures, hybrid infrastructure, and distributed applications, AIOps is becoming a critical component of modern IT operations. By combining intelligence, automation, and predictive analytics, AIOps platforms help businesses operate more efficiently while delivering more reliable digital services.
Common AIOps Challenges and Limitations
AIOps platforms can significantly improve operational efficiency, but they are not a complete solution for every IT challenge.
Successful AIOps adoption requires high-quality data, well-defined processes, and realistic expectations. Organizations that underestimate implementation requirements often struggle to achieve the expected results.
Understanding the common limitations of AIOps helps businesses make better technology decisions and avoid costly mistakes.
Data Quality Issues
AIOps platforms depend heavily on operational data.
Machine learning models analyze logs, metrics, traces, events, and telemetry collected from across the IT environment. If this data is incomplete, inaccurate, or inconsistent, the quality of AIOps insights will decline.
Many organizations operate multiple monitoring tools that use different formats and naming conventions. Inconsistent data can make event correlation and anomaly detection less effective.
Poor data quality may also increase false alerts and reduce confidence in AI-driven recommendations.
Before implementing AIOps, organizations should ensure their monitoring and observability systems provide reliable and standardized data.
Implementation Complexity
Deploying an AIOps platform is often more complex than deploying a traditional monitoring tool.
The platform must connect with monitoring systems, cloud services, applications, infrastructure components, ITSM solutions, and automation workflows.
Large enterprises may need to integrate data from hundreds of technology systems.
Organizations frequently underestimate the time required for configuration, data normalization, workflow design, and operational tuning.
The most successful implementations usually begin with clearly defined use cases rather than attempting to automate every operational process at once.
False Positives and Alert Accuracy
Machine learning models continuously analyze operational patterns and identify unusual behavior.
While these capabilities provide significant value, no AI model is perfect.
AIOps platforms may occasionally classify normal behavior as an anomaly. These false positives can create unnecessary alerts and distract operations teams.
Conversely, some platforms may overlook subtle issues if historical training data is limited.
Reducing false positives often requires ongoing tuning, threshold adjustments, and refinement of machine learning models.
Organizations should view AIOps as a decision-support system rather than a fully autonomous operational platform.
Training and Skill Requirements
AIOps reduces manual effort, but it does not eliminate the need for skilled IT professionals.
Operations teams must understand how the platform collects data, generates insights, and automates workflows.
Without proper training, teams may struggle to interpret AI-generated recommendations or trust automated decisions.
Organizations should invest in training programs that help administrators, engineers, and operations teams understand both the platform and the underlying operational processes.
The combination of human expertise and AI-driven intelligence generally produces the best outcomes.
Integration Challenges
Most enterprises operate a diverse technology ecosystem.
Monitoring tools, cloud platforms, ITSM systems, security solutions, databases, and collaboration tools often come from different vendors.
Integrating these systems into a unified AIOps environment can be challenging.
Some integrations may require custom connectors, API development, or additional configuration work. Data compatibility issues can also affect operational visibility.
The effectiveness of an AIOps platform often depends on how well it integrates with existing operational processes and technology investments.
Organizations should evaluate integration capabilities carefully before selecting a platform.
Cost and ROI Considerations
AIOps platforms can deliver significant operational benefits, but implementation costs can be substantial.
Licensing fees, infrastructure requirements, deployment services, integration projects, and staff training all contribute to the overall investment.
Smaller organizations may struggle to justify advanced enterprise AIOps platforms if operational complexity remains relatively low.
Businesses should evaluate expected benefits against implementation costs and focus on measurable operational improvements such as reduced downtime, faster incident resolution, and improved service reliability.
Summary of Common AIOps Challenges
| Challenge | Potential Impact |
| Poor Data Quality | Reduced accuracy and unreliable insights |
| Implementation Complexity | Longer deployment timelines and higher costs |
| False Positives | Alert fatigue and reduced trust in AI recommendations |
| Training Requirements | Slower adoption and operational inefficiencies |
| Integration Challenges | Limited visibility and fragmented workflows |
| Cost Considerations | Difficulty demonstrating return on investment |
AIOps can transform IT operations, but success depends on more than technology alone. Organizations must combine high-quality data, skilled teams, strong operational processes, and realistic implementation plans.
Businesses that address these challenges early are far more likely to achieve long-term value from their AIOps investments.
Best AIOps Tool for Small and Mid-Sized Businesses
Many AIOps platforms are designed for large enterprises with extensive IT teams and complex infrastructures. However, small and mid-sized businesses (SMBs) also face challenges such as alert fatigue, cloud complexity, limited staffing, and increasing operational demands.
The difference is that SMBs often need solutions that are easier to deploy, simpler to manage, and more affordable than enterprise-focused platforms.
For most SMBs, the best AIOps platform balances visibility, automation, scalability, and cost efficiency.
What SMBs Should Look for in an AIOps Platform
Small and mid-sized businesses typically operate with lean IT teams.
As a result, ease of deployment and operational simplicity are often more important than having every advanced enterprise feature.
When evaluating AIOps tools, SMBs should prioritize:
- Rapid deployment and simple configuration
- Built-in automation and intelligent alerting
- Flexible pricing that scales with business growth
The goal is to reduce operational workload rather than create additional management complexity.
LogicMonitor: Best Overall for SMBs
LogicMonitor offers one of the best balances of monitoring, automation, and ease of deployment for small and mid-sized businesses.
Its cloud-based architecture eliminates much of the infrastructure management required by traditional monitoring platforms. Automated discovery helps teams gain visibility into servers, applications, networks, and cloud resources without lengthy setup processes.
The platform also includes anomaly detection, event correlation, operational dashboards, and predictive insights that help organizations identify issues before they become critical.
For businesses with limited IT staff, LogicMonitor’s simplicity is one of its strongest advantages.
Why SMBs Choose LogicMonitor
- Easy deployment and automated discovery
- Strong hybrid infrastructure visibility
- Lower operational overhead than many enterprise platforms
Datadog: Best for Cloud-First Businesses
Datadog is an excellent option for SMBs operating cloud-native environments.
The platform provides visibility across applications, infrastructure, containers, databases, and cloud services through a unified interface. Its extensive integration ecosystem allows businesses to connect existing tools quickly without major implementation projects.
Datadog’s machine learning capabilities help reduce alert noise and improve incident detection. Teams can monitor rapidly growing environments without significantly increasing operational effort.
Although costs can increase as deployments expand, many growing businesses appreciate Datadog’s flexibility and scalability.
Why SMBs Choose Datadog
- Fast deployment and cloud-native design
- Extensive integrations and monitoring coverage
- Strong scalability for growing organizations
New Relic: Best for Application-Focused Teams
New Relic is a strong choice for SMBs that prioritize application performance and customer experience.
The platform combines application monitoring, infrastructure visibility, distributed tracing, and operational analytics within a single observability environment.
Its unified telemetry model simplifies troubleshooting by allowing teams to analyze logs, metrics, and traces together.
New Relic also provides intelligent alerting and anomaly detection capabilities that help smaller teams identify issues quickly without extensive manual analysis.
For software companies and SaaS providers, New Relic often delivers an excellent balance between visibility and operational simplicity.
Why SMBs Choose New Relic
- Strong application performance monitoring
- Flexible usage-based pricing
- Easy access to observability and AIOps capabilities
SMB AIOps Comparison Table
| Platform | Best For | Ease of Deployment | Automation | Pricing Flexibility |
| LogicMonitor | Hybrid infrastructure | Excellent | Strong | Good |
| Datadog | Cloud-first businesses | Excellent | Strong | Moderate |
| New Relic | Application-focused teams | Very Good | Good | Excellent |
Which AIOps Tool Should SMBs Choose?
For most small and mid-sized businesses, LogicMonitor offers the best overall balance of deployment simplicity, automation, and infrastructure visibility.
Datadog is often the strongest choice for organizations operating primarily in cloud environments and expecting rapid growth.
New Relic is particularly attractive for businesses that depend heavily on application performance and customer experience.
The best choice ultimately depends on infrastructure complexity, operational priorities, available resources, and long-term growth plans.
Organizations should focus on solutions that simplify operations and improve visibility without introducing unnecessary complexity.
Best AIOps Platforms for Enterprise Operations
Enterprise environments generate significantly more operational data than small and mid-sized businesses. Large organizations often manage hybrid infrastructure, multi-cloud deployments, thousands of applications, and mission-critical business services.
As a result, enterprise AIOps platforms require advanced automation, strong scalability, service intelligence, and deep integration capabilities.
Dynatrace is one of the strongest choices for enterprises seeking full-stack observability and AI-driven root cause analysis. Splunk ITSI excels in service-centric operations and business impact visibility. IBM Cloud Pak for AIOps focuses heavily on automation, operational resilience, and hybrid cloud management.
Organizations with complex operational environments may also consider ScienceLogic and BigPanda for service visibility and event intelligence.
The best enterprise AIOps platform depends on operational maturity, infrastructure complexity, compliance requirements, and automation goals.
Future Trends in AIOps
AIOps is evolving rapidly as artificial intelligence becomes more capable and operational environments become more complex.
Early AIOps platforms focused primarily on anomaly detection, event correlation, and alert reduction. Modern platforms are expanding far beyond these capabilities.
Over the next several years, AIOps will become more autonomous, predictive, and tightly integrated with enterprise operations.
Organizations investing in AIOps today should understand the technologies that will shape the next generation of intelligent IT operations.
Generative AI in IT Operations
Generative AI is beginning to transform how operations teams interact with monitoring and observability platforms.
Instead of manually searching dashboards and logs, engineers can use natural language queries to investigate incidents, analyze performance issues, and generate operational reports.
Future AIOps platforms will increasingly use large language models (LLMs) to summarize incidents, explain root causes, recommend remediation steps, and provide operational guidance.
This will make advanced operational analytics more accessible to teams with varying levels of technical expertise.
Generative AI will also reduce the time required to interpret complex operational data during high-pressure incidents.
Autonomous Incident Response
Most AIOps platforms currently assist human operators during incident response.
The next generation of platforms will move toward autonomous incident management.
When incidents occur, AI systems will automatically investigate operational data, identify probable causes, determine remediation options, and execute predefined workflows.
Human teams will remain involved in high-risk decisions, but routine operational incidents will increasingly be handled with minimal manual intervention.
This shift will help organizations reduce response times and improve operational consistency.
AI Agents for Operations
AI agents represent one of the most important emerging trends in AIOps.
Unlike traditional automation workflows, AI agents can reason through operational problems, evaluate multiple data sources, and perform multi-step actions independently.
Future operations teams may work alongside specialized AI agents responsible for infrastructure monitoring, incident investigation, capacity planning, security analysis, and performance optimization.
These agents will act as digital operations assistants that continuously monitor environments and proactively address issues.
As agent-based AI matures, organizations may automate a growing percentage of routine operational work.
Predictive Remediation
Most AIOps platforms already support predictive analytics.
The next step is predictive remediation.
Rather than simply forecasting future risks, platforms will automatically recommend or execute corrective actions before problems affect services.
For example, an AIOps platform may detect abnormal resource consumption patterns and automatically scale infrastructure before performance degrades.
Similarly, capacity constraints may be addressed automatically before they create service disruptions.
Predictive remediation has the potential to significantly reduce downtime and improve operational resilience.
AI-Powered Observability
Observability platforms are becoming increasingly intelligent.
Traditional observability focuses on collecting logs, metrics, traces, and telemetry data. AI-powered observability adds automated analysis, contextual insights, and operational recommendations.
Future observability platforms will automatically identify abnormal patterns, explain service dependencies, highlight business impact, and prioritize incidents without requiring extensive manual investigation.
This convergence of observability and artificial intelligence will make operational data more actionable and easier to understand.
Many vendors are already integrating AI capabilities directly into observability workflows.
Self-Healing Infrastructure
Self-healing infrastructure is one of the most ambitious goals of modern IT operations.
In a self-healing environment, systems can detect issues, diagnose causes, and implement corrective actions automatically.
Examples may include restarting failed services, reallocating resources, repairing configuration issues, scaling infrastructure, or isolating unhealthy components without human intervention.
AIOps platforms play a critical role in enabling these capabilities because they provide the intelligence required to recognize problems and determine appropriate responses.
While fully autonomous infrastructure remains a long-term objective, many organizations are already implementing limited self-healing capabilities through automation and AIOps technologies.
The Future of AIOps
The future of AIOps extends beyond monitoring and alert management.
Artificial intelligence is transforming IT operations into a more proactive, predictive, and automated discipline.
Technologies such as generative AI, autonomous incident response, AI agents, predictive remediation, AI-powered observability, and self-healing infrastructure are pushing AIOps toward a new level of operational maturity.
Organizations that adopt these technologies early will be better positioned to manage growing infrastructure complexity while improving service reliability, operational efficiency, and business resilience.
Over the next decade, AIOps is expected to become a foundational component of modern digital operations rather than an optional enhancement to traditional monitoring.
Frequently Asked Questions
What are AIOps tools?
AIOps tools use artificial intelligence, machine learning, and automation to improve IT operations. They analyze operational data from logs, metrics, traces, and events to detect anomalies, correlate alerts, identify root causes, and automate incident response.
Organizations use AIOps platforms to reduce alert fatigue, improve service reliability, and accelerate incident resolution across modern IT environments.
What is the difference between AIOps and DevOps?
DevOps is a cultural and operational approach that improves collaboration between development and operations teams. Its goal is to accelerate software delivery while maintaining system reliability.
AIOps is a technology-driven approach that applies artificial intelligence and machine learning to IT operations.
In simple terms, DevOps focuses on how teams work together, while AIOps focuses on how AI helps manage and automate operational tasks.
Many organizations use both approaches together.
Is AIOps the same as observability?
No.
Observability focuses on collecting and analyzing logs, metrics, traces, and telemetry data to understand system behavior.
AIOps uses that data to automate analysis, identify anomalies, correlate events, and support operational decision-making.
Observability provides visibility into systems. AIOps adds intelligence and automation to that visibility.
Many modern platforms combine observability and AIOps capabilities within a single solution.
Which is the best AIOps platform?
The best AIOps platform depends on business requirements, infrastructure complexity, and operational goals.
Dynatrace is often considered one of the strongest overall AIOps platforms because of its advanced AI capabilities and full-stack observability.
Datadog is a popular choice for cloud-native organizations. Splunk ITSI excels in enterprise service intelligence, while LogicMonitor offers strong value for hybrid infrastructure environments.
Organizations should evaluate platforms based on scalability, automation capabilities, integrations, and long-term operational needs.
Can AIOps reduce downtime?
Yes.
AIOps platforms help reduce downtime by identifying anomalies earlier, correlating related events, automating incident investigation, and accelerating root cause analysis.
Many platforms also provide predictive analytics that help organizations detect operational risks before they affect users.
By improving detection and response times, AIOps can significantly improve service availability and operational resilience.
How does AIOps use machine learning?
Machine learning is one of the core technologies behind AIOps.
AIOps platforms continuously analyze operational data to establish normal performance patterns. The system then compares real-time behavior against these baselines to identify anomalies and unusual activity.
Machine learning also supports event correlation, incident prioritization, predictive analytics, and root cause analysis.
As the platform processes more operational data, its ability to identify patterns and provide actionable insights improves over time.
Conclusion
Managing modern IT environments has become increasingly challenging. Organizations must support cloud-native applications, hybrid infrastructure, distributed services, and growing volumes of operational data.
Traditional monitoring tools still play an important role, but they often struggle to keep pace with the scale and complexity of today’s technology environments.
AIOps platforms address these challenges by combining artificial intelligence, machine learning, and automation with operational workflows. They help organizations reduce alert fatigue, accelerate incident response, improve root cause analysis, and automate repetitive operational tasks.
As cloud complexity continues to increase, businesses need more than visibility alone. They need intelligent systems that can analyze operational data, identify risks, and support proactive decision-making.
The leading AIOps platforms in 2026, including Dynatrace, Datadog, Splunk ITSI, New Relic, LogicMonitor, PagerDuty AIOps, BigPanda, Moogsoft, IBM Cloud Pak for AIOps, and ScienceLogic, provide a wide range of capabilities to meet these needs.
The best choice depends on infrastructure requirements, operational maturity, automation goals, and budget. Organizations should evaluate platforms based on scalability, integration capabilities, AI-driven insights, and long-term business value.
Looking ahead, the future of AIOps will be shaped by generative AI, autonomous incident response, AI agents, predictive remediation, and self-healing infrastructure. These technologies are moving IT operations from reactive management toward intelligent and increasingly autonomous operations.
For organizations seeking greater operational efficiency, improved service reliability, and stronger resilience, AIOps is rapidly becoming a foundational component of modern IT operations rather than an optional enhancement.
As digital environments continue to evolve, AI-driven operations will play an increasingly important role in helping businesses maintain performance, reduce downtime, and deliver reliable user experiences at scale.
About the Author
Rajkumar RR is a technology writer, SEO strategist, and digital publisher focused on cybersecurity, cloud computing, AI, and emerging enterprise technologies. Through ProDigitalWeb.com, he publishes in-depth guides, technical explainers, and research-driven articles covering cyber resilience, SaaS infrastructure, cloud security, and next-generation computing trends.
His work focuses on making complex technology topics easier to understand while maintaining technical depth and practical relevance for professionals, businesses, and technology enthusiasts worldwide.
About the Editor
Dharini R is an editor and content reviewer at ProDigitalWeb.com, where she helps refine technology and cybersecurity content for clarity, readability, and accuracy. She specializes in structuring long-form technical articles, improving content quality, and ensuring that complex topics remain accessible to a broad global audience.
Her editorial focus includes cloud computing, SaaS technologies, cybersecurity trends, and emerging digital innovations.
Last Updated: June 24, 2026 | Reviewed for accuracy and relevance





